
Nowoczesne modele językowe w ciągu kilku sekund przetwarzają ogromne ilości danych, a następnie wybierają jedynie te źródła, które uznają za najbardziej wiarygodne i użyteczne. To właśnie na ich podstawie tworzą odpowiedzi dla użytkowników. Jeśli Twoja witryna nie zostanie rozpoznana jako wartościowe źródło informacji, jej treści mogą pozostać niewidoczne dla potencjalnych klientów.
Na szczęście nie jest to proces oparty na przypadku.
Widoczność w odpowiedziach generowanych przez AI można analizować, mierzyć i systematycznie zwiększać dzięki odpowiednio zaplanowanej optymalizacji.
Od SEO do GEO. Na czym polega zmiana paradygmatu?
Przez lata skuteczność działań SEO oceniano przede wszystkim za pomocą wskaźnika Share of Voice. Określał on, jaki udział w ruchu z wyszukiwarki zdobywa dana domena dla wybranych słów kluczowych w tradycyjnych wynikach Google.
Dziś coraz większego znaczenia nabiera jednak inna metryka – Share of Source, czyli udział w źródłach wykorzystywanych przez systemy sztucznej inteligencji.
Share of Source pokazuje, jak często treści z danej witryny są wskazywane jako źródło informacji i cytowane w odpowiedziach generowanych przez AI. O ile wcześniej celem było osiągnięcie jak najwyższej pozycji na liście wyników wyszukiwania, o tyle obecnie kluczowe staje się dostarczenie informacji na tyle wiarygodnych i wartościowych, aby model językowy wykorzystał je podczas tworzenia odpowiedzi.
Wraz z rozwojem wyszukiwarek opartych na sztucznej inteligencji zmieniają się również zasady optymalizacji. Tradycyjne działania, takie jak nadmierne nasycanie treści słowami kluczowymi czy rozbudowa zaplecza linkowego, tracą na znaczeniu.
Coraz większą rolę odgrywa GEO (Generative Engine Optimization), czyli podejście skupione na przygotowaniu treści i struktury danych w sposób ułatwiający systemom AI ich szybkie odnalezienie, interpretację oraz wykorzystanie jako wiarygodnego źródła informacji.
Analizy rynku wskazują, że ruch pochodzący z platform opartych na sztucznej inteligencji, takich jak ChatGPT czy Gemini, często charakteryzuje się wyższym współczynnikiem konwersji niż tradycyjny ruch organiczny z wyszukiwarek internetowych.
Wynika to przede wszystkim z intencji użytkowników. Osoby korzystające z narzędzi AI zazwyczaj poszukują konkretnych odpowiedzi, rekomendacji lub rozwiązań, a nie listy stron do samodzielnego przeanalizowania.
Gdy system sztucznej inteligencji wskaże określony produkt, usługę lub firmę, a jednocześnie oprze swoją odpowiedź na informacjach pochodzących z danej witryny, prawdopodobieństwo wykonania pożądanej akcji – zakupu, kontaktu czy wysłania zapytania – znacząco wzrasta.
Dlaczego system AI wybiera akurat ten artykuł?
Większość nowoczesnych asystentów AI, w tym ChatGPT, Gemini czy Perplexity, wykorzystuje rozwiązania oparte na architekturze RAG (Retrieval-Augmented Generation).
W praktyce oznacza to, że model najpierw wyszukuje informacje w dostępnych źródłach, a dopiero później generuje odpowiedź dla użytkownika. Zanim jednak dane zostaną wykorzystane, przechodzą przez proces oceny jakości i przydatności.
Jednym z najważniejszych kryteriów jest trafność semantyczna. Treść powinna wprost odpowiadać na pytanie użytkownika i dostarczać konkretnych informacji, bez zbędnych dygresji.
Równie istotna jest przejrzysta struktura strony.
Nagłówki, tabele, listy oraz poprawnie zastosowane znaczniki HTML ułatwiają systemom AI interpretację i porządkowanie danych. Znaczenie ma także aktualność informacji oraz obecność konkretnych danych, przykładów i faktów potwierdzających wiarygodność treści.
Z tego względu coraz większą rolę odgrywa metoda BLUF (Bottom Line Up Front), polegająca na przedstawieniu najważniejszych informacji już na początku sekcji lub akapitu. Modele AI podczas analizy treści poszukują szybkich i jednoznacznych odpowiedzi, dlatego kluczowe wnioski, definicje czy rekomendacje warto umieszczać na samym początku. Dopiero w dalszej części tekstu powinno znaleźć się rozwinięcie, dodatkowe wyjaśnienia i szerszy kontekst.
Plik robots.txt – jak zarządzać dostępem botów AI?
Jednym z pierwszych kroków w optymalizacji witryny pod kątem wyszukiwarek AI jest sprawdzenie, czy roboty odpowiedzialne za indeksowanie i wyszukiwanie treści mają dostęp do strony (czyli jaką ma treść plik robots.txt umieszczony na serwerze).
Nawet wartościowe i dobrze zoptymalizowane materiały nie pojawią się w odpowiedziach generowanych przez sztuczną inteligencję, jeśli odpowiednie boty zostaną zablokowane na poziomie serwera. Podstawowym narzędziem kontroli dostępu jest plik robots.txt znajdujący się w katalogu głównym witryny.
Wokół botów AI narosło wiele nieporozumień.
Część właścicieli stron blokuje wszystkie roboty powiązane ze sztuczną inteligencją, chcąc uniemożliwić wykorzystywanie swoich treści do trenowania modeli. Takie podejście może jednak nieświadomie ograniczyć widoczność witryny w odpowiedziach generowanych przez AI. Kluczowe jest zrozumienie, że nie wszystkie boty pełnią tę samą funkcję.
Przykładowo GPTBot służy przede wszystkim do pozyskiwania danych wykorzystywanych przy rozwijaniu i trenowaniu modeli OpenAI. Z kolei OAI-SearchBot odpowiada za wyszukiwanie oraz pobieranie treści wykorzystywanych podczas prezentowania wyników i odpowiedzi użytkownikom.
Podobną rolę w ekosystemie Perplexity pełni PerplexityBot. Zablokowanie robotów odpowiedzialnych za wyszukiwanie może sprawić, że treści przestaną być uwzględniane w odpowiedziach generowanych przez narzędzia AI, nawet jeśli pozostają widoczne w tradycyjnych wynikach wyszukiwania.
Aby sprawdzić konfigurację, zaloguj się do panelu hostingowego lub połącz z serwerem za pomocą klienta FTP. Następnie odszukaj plik robots.txt znajdujący się w katalogu głównym domeny, najczęściej w folderze public_html. Warto upewnić się, że nie zawiera on reguł blokujących dostęp robotom odpowiedzialnym za wyszukiwanie i indeksowanie treści.
Jeżeli zależy Ci na ograniczeniu wykorzystania materiałów do trenowania modeli AI, a jednocześnie chcesz zachować widoczność w odpowiedziach generowanych przez sztuczną inteligencję, możesz zablokować boty treningowe, pozostawiając dostęp botom wyszukującym:
User-agent: OAI-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: GPTBot
Disallow: /
Po zapisaniu zmian warto sprawdzić poprawność konfiguracji oraz regularnie monitorować dokumentację dostawców usług AI.
Rozwój wyszukiwarek opartych na sztucznej inteligencji jest bardzo dynamiczny, dlatego lista wykorzystywanych botów i ich funkcje mogą z czasem ulegać zmianom.
Najważniejsza zasada jest prosta: blokowanie botów odpowiedzialnych za trenowanie modeli nie musi oznaczać rezygnacji z widoczności w odpowiedziach AI.

Aby zachować szansę na pojawianie się w wynikach generowanych przez systemy sztucznej inteligencji, należy zadbać o to, by roboty wyszukujące i indeksujące treści nadal miały dostęp do witryny.
Plik llms.txt – dodatkowa mapa treści dla systemów AI
Tradycyjny kod HTML strony zawiera wiele elementów, które nie mają znaczenia dla modeli językowych. Menu nawigacyjne, skrypty analityczne, reklamy, style CSS czy komponenty interfejsu są niezbędne dla użytkowników, ale utrudniają szybkie dotarcie do właściwej treści.
Z tego powodu coraz większe zainteresowanie budzi koncepcja pliku llms.txt, który pełni rolę uproszczonego przewodnika po najważniejszych zasobach witryny.
Plik llms.txt umieszcza się w katalogu głównym strony, podobnie jak robots.txt. Jego zadaniem jest wskazanie najcenniejszych sekcji serwisu w uporządkowanej, łatwej do przetworzenia formie.
Zamiast analizować całą strukturę witryny, system AI może szybciej zidentyfikować strony zawierające kluczowe informacje, dokumentację, poradniki czy artykuły eksperckie.
W praktyce plik zawiera listę najważniejszych adresów URL wraz z krótkim opisem ich zawartości. Najczęściej wykorzystuje się do tego prosty format Markdown, który jest czytelny zarówno dla ludzi, jak i systemów przetwarzających tekst.
Jak utworzyć plik llms.txt?
Przygotowanie pliku jest stosunkowo proste i nie wymaga zaawansowanej wiedzy technicznej.
W pierwszej kolejności utwórz nowy plik tekstowy i zapisz go pod nazwą llms.txt.
Następnie dodaj odnośniki do najważniejszych sekcji witryny wraz z krótkim opisem ich zawartości.
Przykładowa zawartość pliku llms.txt może wyglądać następująco:
# Strona firmowa XYZ
## Baza wiedzy
[Baza Wiedzy](https://twojadomena.pl/baza-wiedzy)
Eksperckie artykuły dotyczące SEO, GEO i marketingu internetowego.
## Dokumentacja
[Dokumentacja](https://twojadomena.pl/dokumentacja)
Instrukcje, poradniki i materiały techniczne dla klientów.
Po przygotowaniu pliku należy umieścić go w katalogu głównym witryny, tak aby był dostępny pod adresem: https://twojadomena.pl/llms.txt
Choć llms.txt nie zastępuje mapy strony XML ani standardowych działań SEO, może stanowić dodatkowy sygnał ułatwiający systemom AI odnalezienie najważniejszych treści.
W przypadku rozbudowanych serwisów z dużą liczbą artykułów, dokumentacji lub materiałów eksperckich pozwala także lepiej uporządkować zasoby przeznaczone do indeksowania i analizy.
Choć llms.txt nie zastępuje mapy strony XML ani standardowych działań SEO, może stanowić dodatkowy sygnał ułatwiający systemom AI odnalezienie najważniejszych treści.
W przypadku rozbudowanych serwisów z dużą liczbą artykułów, dokumentacji lub materiałów eksperckich pozwala także lepiej uporządkować zasoby przeznaczone do indeksowania i analizy.
Jak mierzyć ruch pochodzący z wyszukiwarek AI w Google Analytics 4?
Jednym z największych wyzwań związanych z optymalizacją pod wyszukiwarki AI jest pomiar efektów prowadzonych działań.
W przeciwieństwie do tradycyjnych wyszukiwarek ruch pochodzący z narzędzi takich jak ChatGPT, Perplexity czy Gemini nie zawsze jest jednoznacznie klasyfikowany w raportach analitycznych.
Część wizyt przekazuje informacje o źródle, inne mogą zostać przypisane do kanałów Direct, Referral lub Unassigned, co utrudnia ocenę rzeczywistego wpływu ruchu generowanego przez AI.
Aby uzyskać pełniejszy obraz sytuacji, warto utworzyć w Google Analytics 4 dedykowany kanał grupujący wizyty pochodzące z najpopularniejszych platform opartych na sztucznej inteligencji.
Pozwala to monitorować liczbę sesji, zachowanie użytkowników oraz współczynniki konwersji dla tego źródła ruchu.
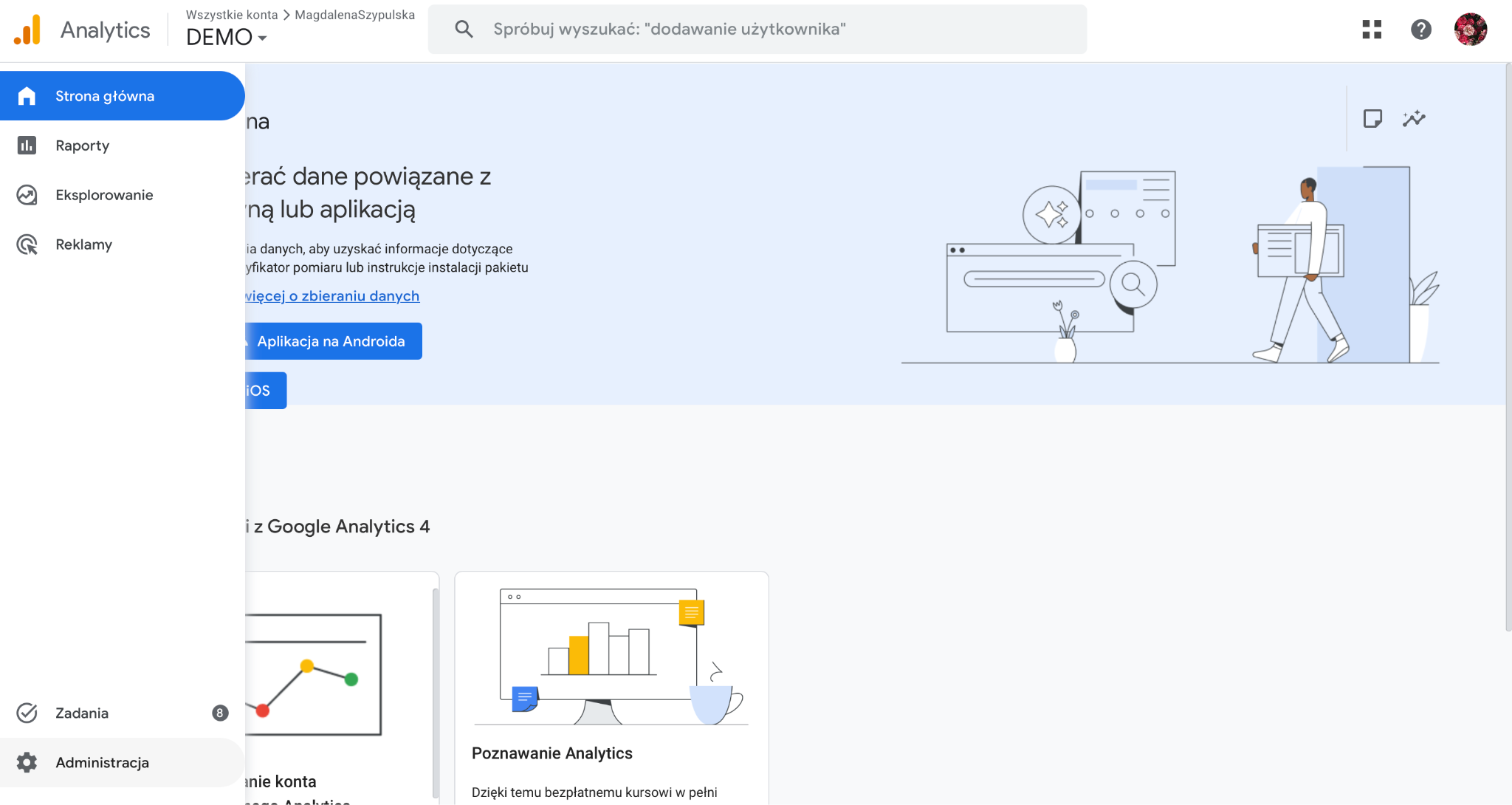
Jak utworzyć kanał „Ruch z AI” w GA4?
W panelu Google Analytics 4 przejdź do sekcji Administracja, a następnie wybierz Grupy kanałów w obszarze odpowiedzialnym za wyświetlanie danych.
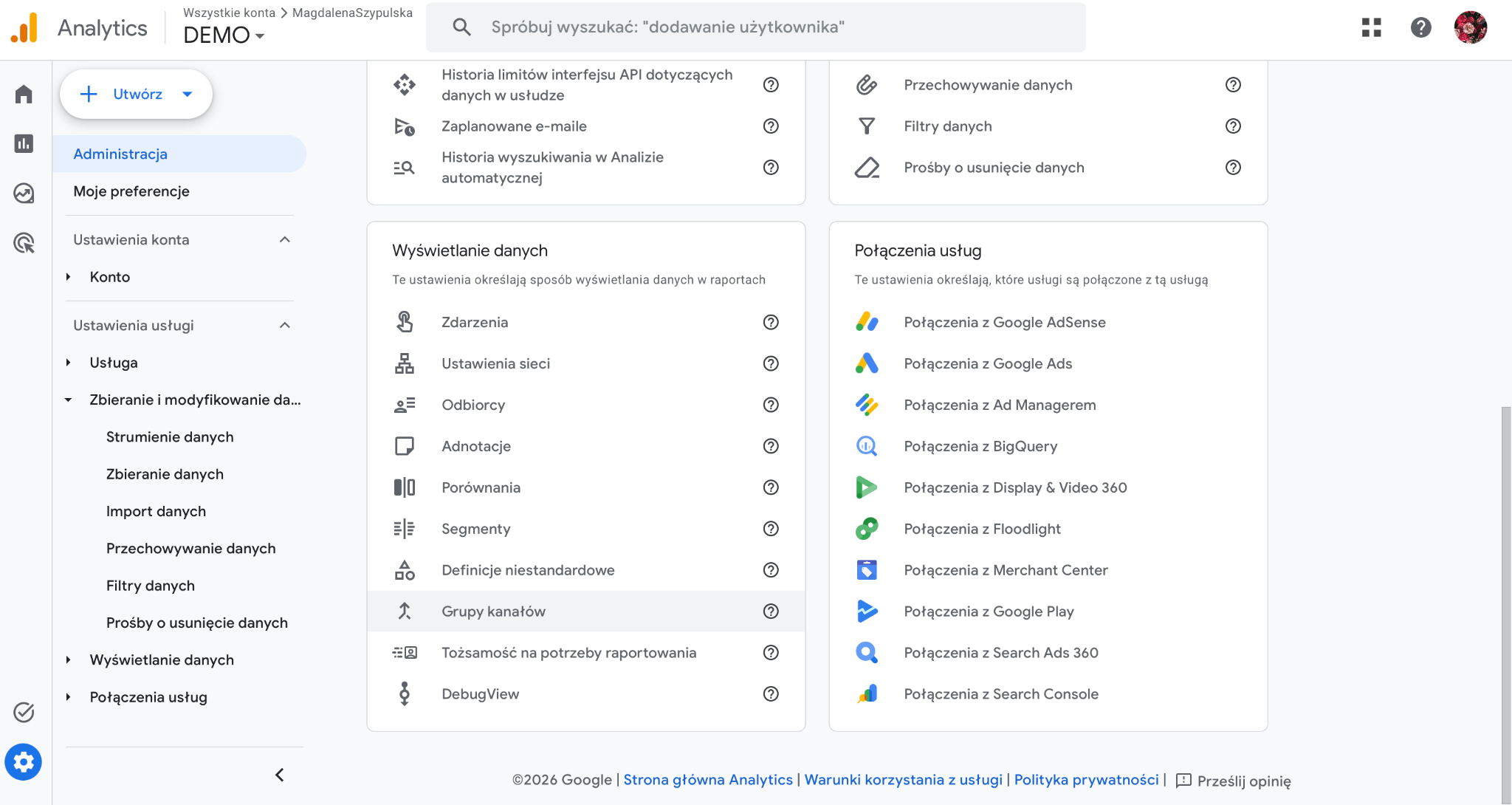
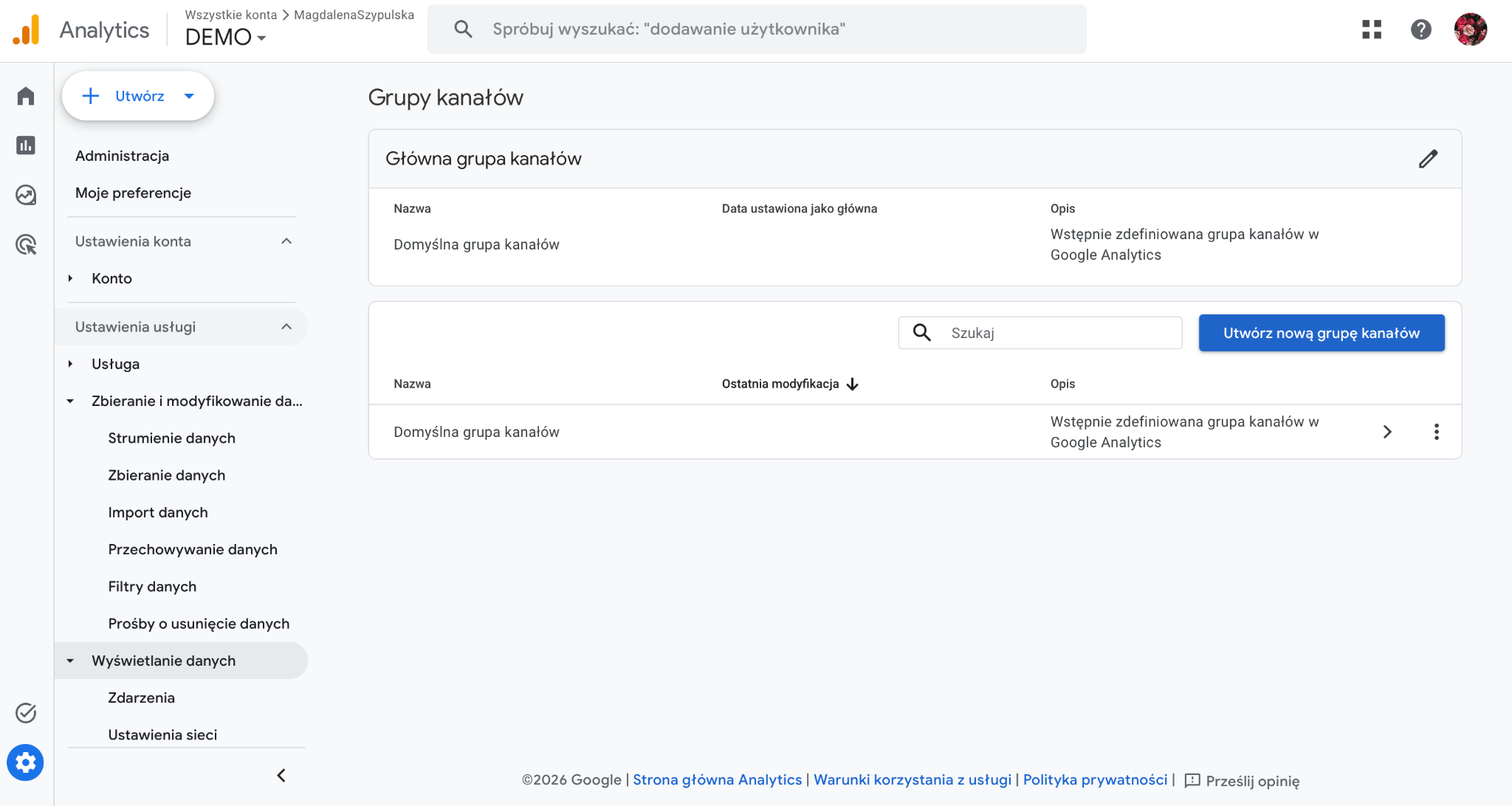
Możesz utworzyć nową grupę kanałów lub edytować istniejącą grupę niestandardową.
Następnie dodaj nową grupę kanałów, nadając jej nazwę, na przykład „Ruch z AI”.
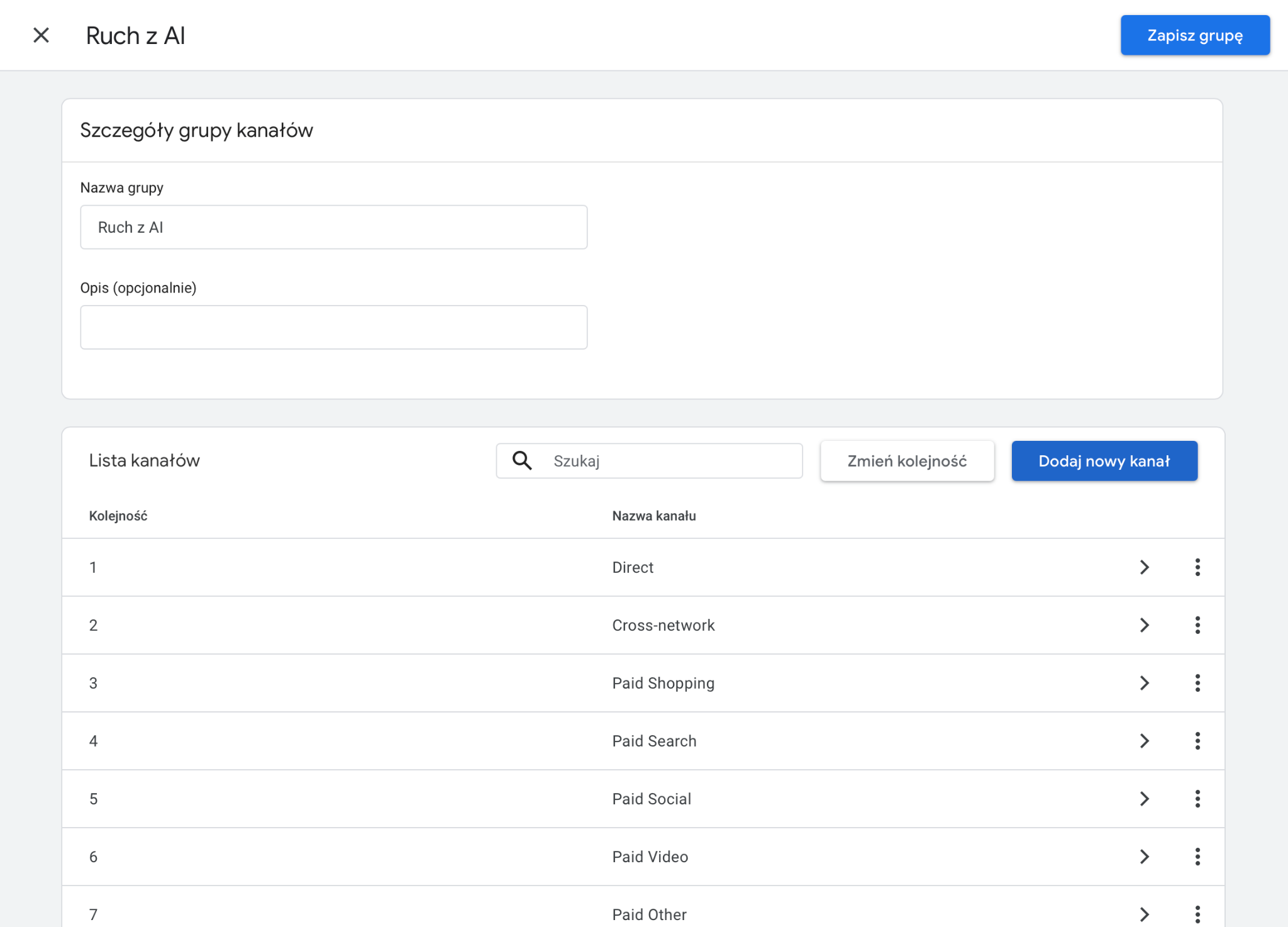
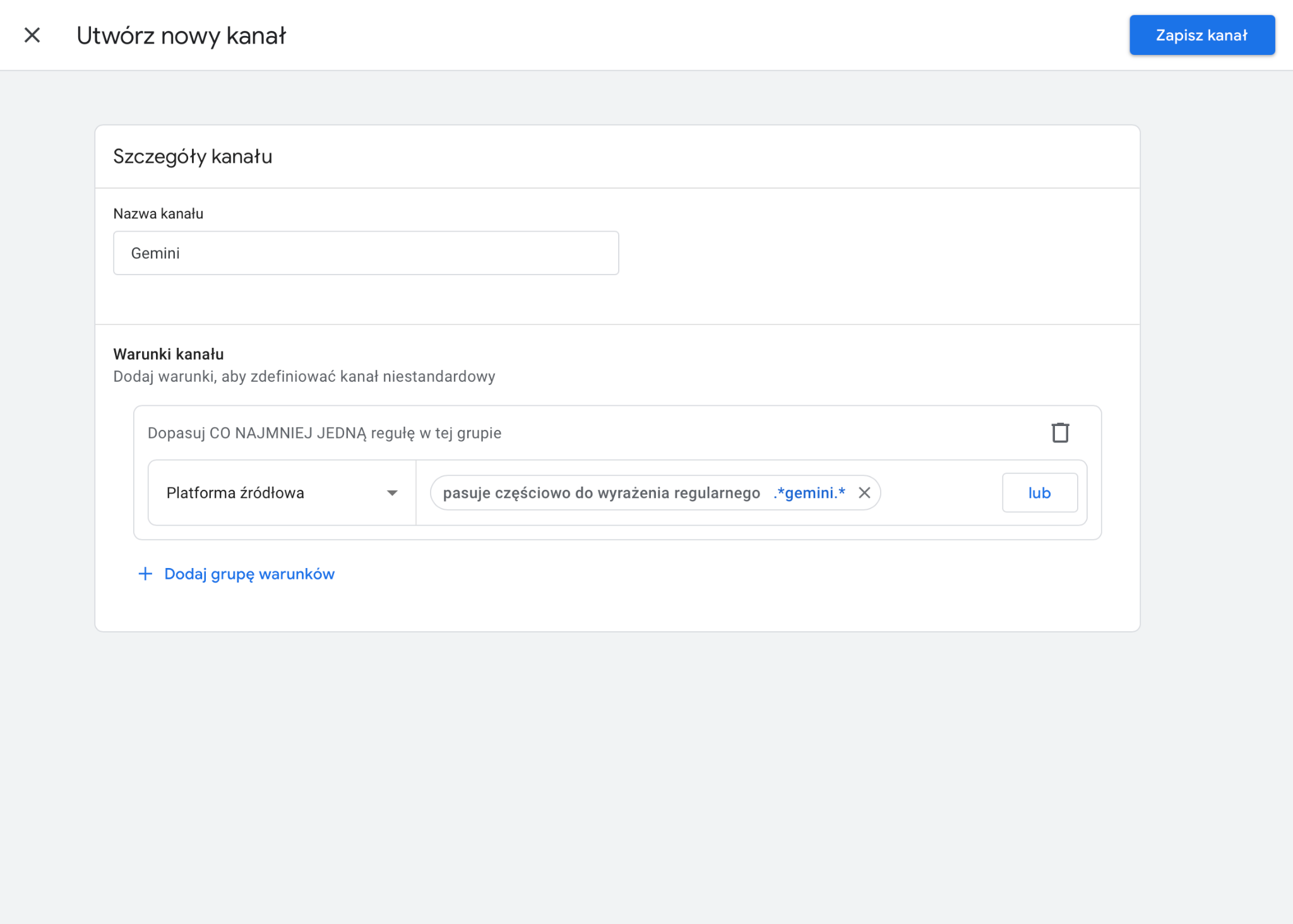
W konfiguracji warunków wybierz parametr Źródło sesji (Session Source), a jako operator ustaw pasuje do wyrażenia regularnego (matches regex).
W zależności od potrzeb możesz utworzyć jeden zbiorczy kanał obejmujący cały ruch z platform AI lub osobne kanały dla każdego narzędzia.
Pierwsze rozwiązanie pozwala szybko ocenić skalę ruchu generowanego przez sztuczną inteligencję, natomiast drugie ułatwia analizę skuteczności poszczególnych platform.
Dla zbiorczego kanału „Ruch z AI” można wykorzystać następujące wyrażenie regularne:
.*chatgpt.*|.*openai.*|.*perplexity.*|.*claude.ai.*|.*gemini.*|.*copilot.*
Jeżeli zależy Ci na bardziej szczegółowych danych, utwórz oddzielne kanały dla poszczególnych źródeł ruchu:
ChatGPT / OpenAI
.*chatgpt.*|.*openai.*
Perplexity
.*perplexity.*
Claude
.*claude.ai.*
Gemini
.*gemini.*
Microsoft Copilot
.*copilot.*
Podczas konfiguracji kanału wybierz warunek „pasuje do wyrażenia regularnego” (matches regex), a następnie wklej odpowiedni wzorzec.
Szczególną uwagę należy zwrócić na kolejność reguł w grupie kanałów.
Google Analytics analizuje je od góry do dołu i przypisuje sesję do pierwszego pasującego kanału.
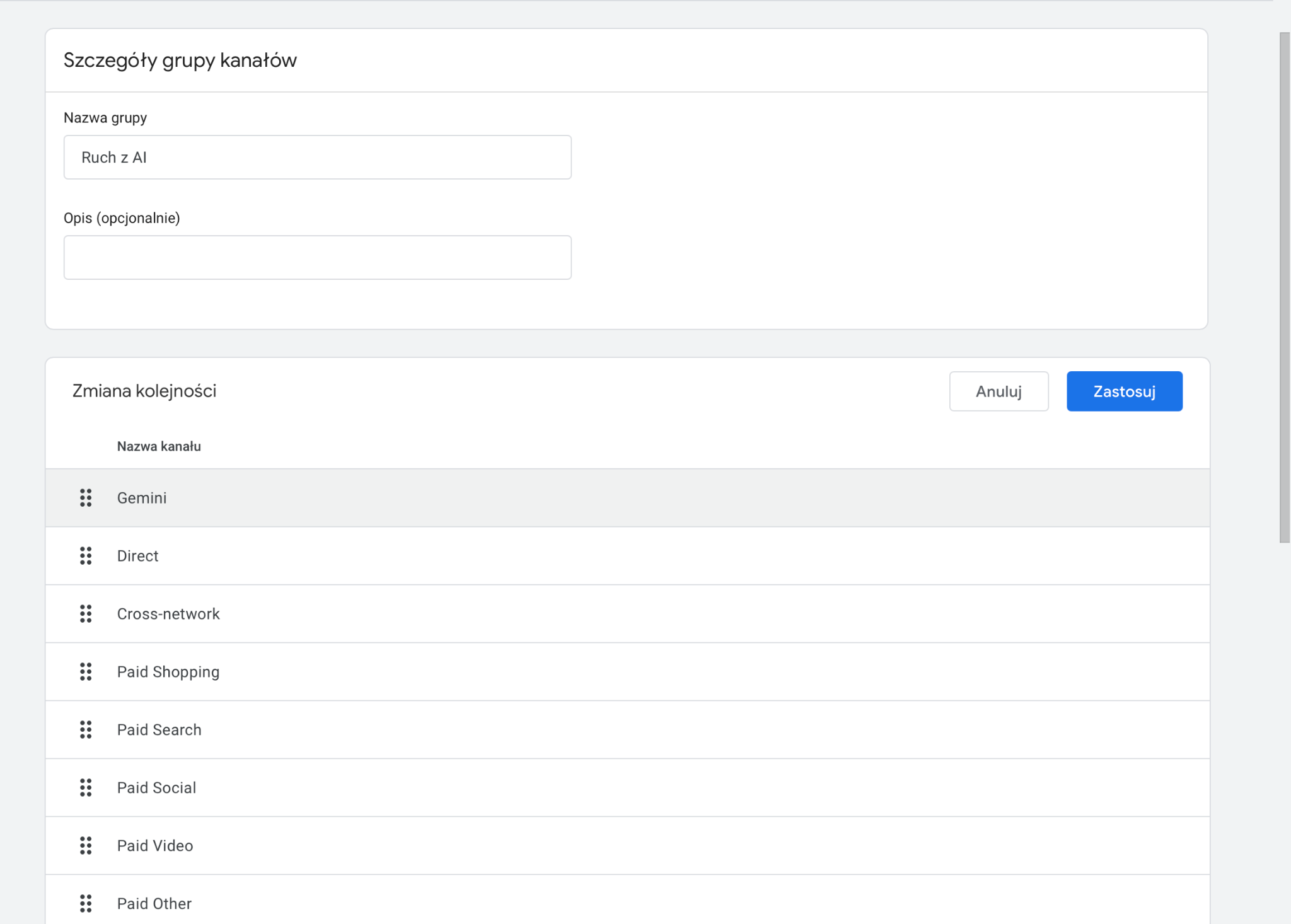
Przenieś nowo utworzony kanał, zatwierdź decyzję przyciskiem “Zastosuj”.
Oznacza to, że nowo utworzony kanał „Ruch z AI” powinien znajdować się powyżej ogólnych reguł, takich jak Referral.
W przeciwnym razie część wizyt zostanie zakwalifikowana do innych kategorii, co utrudni późniejszą analizę.
Po zapisaniu konfiguracji dane zaczną pojawiać się w raportach zgodnie z nowymi zasadami klasyfikacji. Dzięki temu możliwe będzie monitorowanie, jaki udział w ruchu i konwersjach generują użytkownicy trafiający na stronę za pośrednictwem narzędzi opartych na sztucznej inteligencji.
Gdzie dokładnie szukać tych informacji?
Aby znaleźć nową grupę w panelu Google Analytics 4, z menu po lewej stronie wybierz Raporty, następnie rozwiń sekcję Zdobywanie potencjalnych klientów i kliknij Pozyskiwanie ruchu. W głównej tabeli z danymi odnajdziesz swój nowo utworzony kanał „Ruch z AI”.
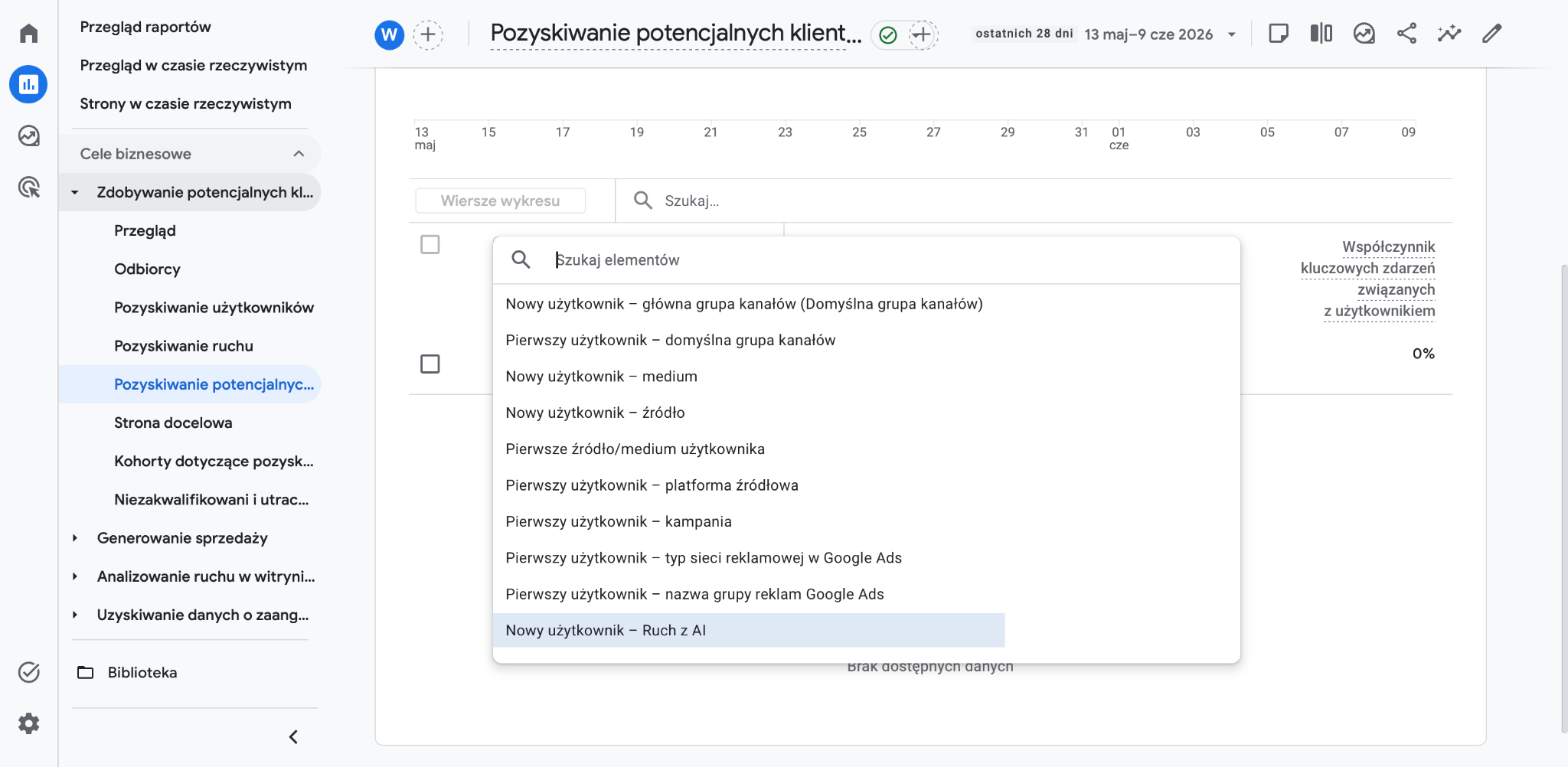
Narzędzia do monitorowania cytowań. Od SaaS po Python
Okazjonalne sprawdzanie widoczności marki poprzez ręczne wpisywanie zapytań do ChatGPT, Gemini czy Perplexity pozwala jedynie uzyskać ogólny obraz sytuacji.
Takie podejście trudno jednak uznać za wiarygodną metodę pomiaru.
Odpowiedzi generowane przez modele językowe mogą różnić się w zależności od kontekstu rozmowy, aktualnych źródeł danych, sposobu sformułowania pytania czy zastosowanych mechanizmów wyszukiwania.
Z tego powodu skuteczny monitoring w obszarze GEO wymaga bardziej systematycznego podejścia.
Na rynku pojawia się coraz więcej narzędzi wyspecjalizowanych w analizie widoczności marek w odpowiedziach generowanych przez sztuczną inteligencję.
Platformy takie jak Otterly.ai czy Profound automatycznie wysyłają zestawy wcześniej zdefiniowanych zapytań do różnych modeli językowych, a następnie analizują odpowiedzi pod kątem obecności wskazanych marek, produktów lub domen.
Darmową, budżetową alternatywą na start jest wykorzystanie bezpłatnego konta w narzędziu Ahrefs (Ahrefs Webmaster Tools). Wystarczy dodać tam swoją domenę jako projekt.
W podstawowych raportach widoczna będzie lista systemów AI, w których pojawiły się cytowania Twojej witryny.
Należy jednak pamiętać, że jest to wersja mocno podstawowa – aby zobaczyć bardziej szczegółowe dane, takie jak konkretne podstrony użyte jako źródło czy dokładne daty cytowań, konieczne jest przejście na płatny pakiet.
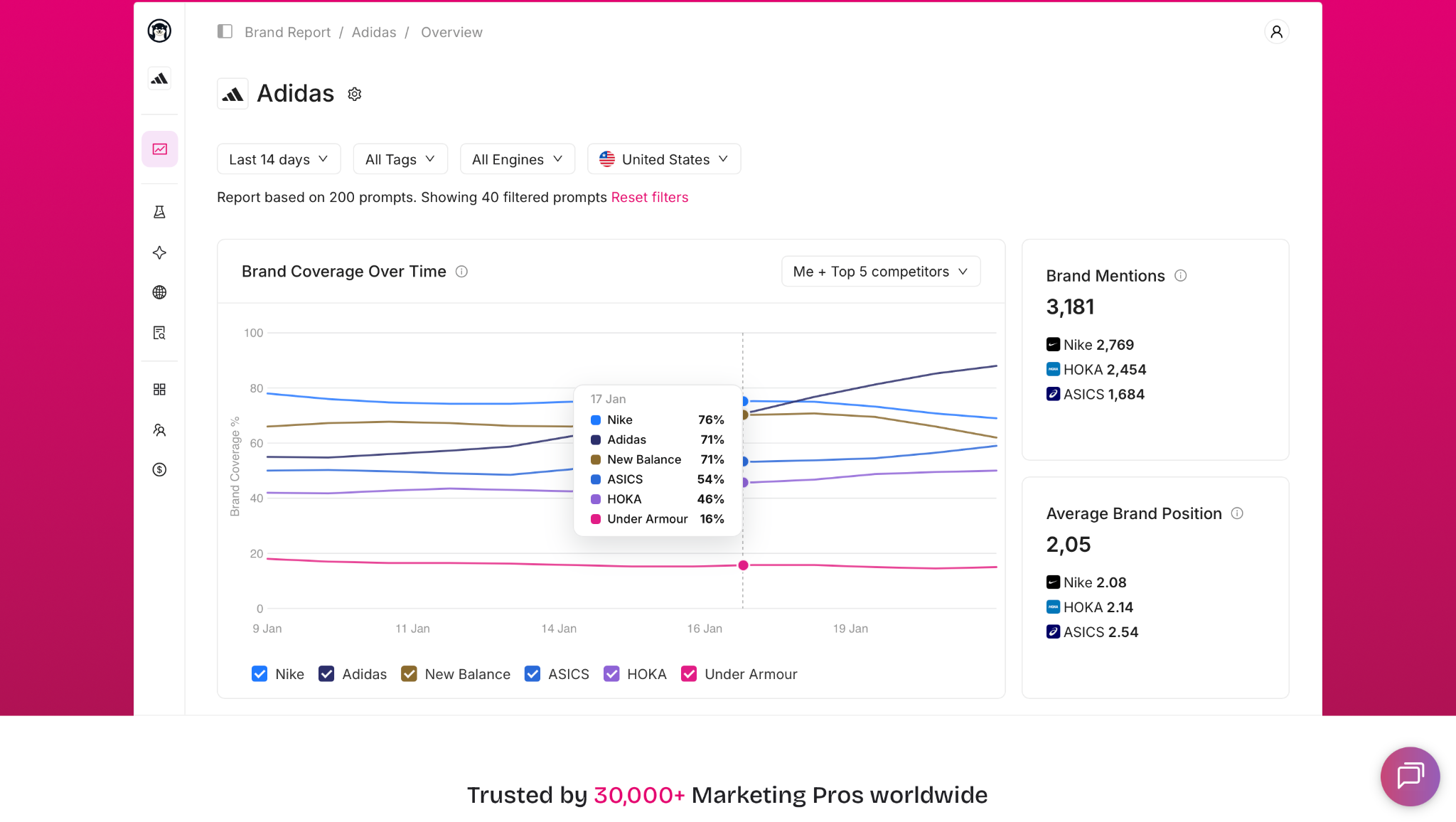
Dzięki temu możliwe jest śledzenie zmian widoczności w czasie oraz identyfikowanie tematów, w których konkurencja jest częściej cytowana jako źródło informacji.
Firmy dysponujące zapleczem technicznym mogą również stworzyć własny system monitoringu.
W praktyce polega to na wykorzystaniu interfejsów API dostarczanych przez dostawców modeli AI do automatycznego zadawania pytań i analizowania uzyskanych odpowiedzi.
Tego typu rozwiązania pozwalają monitorować określone słowa kluczowe, sprawdzać częstotliwość występowania marki oraz identyfikować źródła wskazywane przez modele podczas generowania odpowiedzi.
Największą zaletą automatyzacji jest możliwość regularnego zbierania danych i obserwowania trendów.
Dzięki temu łatwiej wykryć obszary, w których marka jest rzadko cytowana, a następnie uzupełnić treści o brakujące informacje lub rozbudować sekcje odpowiadające na konkretne pytania użytkowników.
W praktyce pozwala to szybciej reagować na zmiany zachodzące w wyszukiwarkach AI i skuteczniej zwiększać udział witryny w źródłach wykorzystywanych przez modele językowe.
Sekcja FAQ
Czym optymalizacja pod AI (GEO) różni się od klasycznego SEO?
SEO i GEO mają wspólny cel – zwiększenie widoczności treści w internecie – jednak wykorzystują nieco inne mechanizmy.
Klasyczne SEO koncentruje się na poprawie pozycji strony w wynikach wyszukiwania poprzez optymalizację treści, architektury serwisu, doświadczeń użytkownika oraz profilu linków. GEO (Generative Engine Optimization) skupia się natomiast na zwiększaniu prawdopodobieństwa, że treść zostanie wykorzystana jako źródło informacji przez systemy sztucznej inteligencji.
W praktyce oznacza to większy nacisk na przejrzystą strukturę informacji, jednoznaczne odpowiedzi, wiarygodne dane oraz formaty ułatwiające analizę przez modele językowe.
Nie chodzi już wyłącznie o zajęcie wysokiej pozycji w wynikach wyszukiwania, ale również o to, aby treść została uznana za wartościowe źródło podczas generowania odpowiedzi przez AI.
Dlaczego ChatGPT częściej wskazuje stronę konkurencji niż moją?
Przyczyn może być wiele.
Modele językowe i systemy wyszukiwania AI preferują treści, które w jasny sposób odpowiadają na konkretne pytania użytkowników.
Jeśli konkurencja publikuje bardziej uporządkowane materiały, wykorzystuje czytelne nagłówki, sekcje z najważniejszymi wnioskami, tabele, listy oraz dane poparte źródłami, jej treści mogą być łatwiejsze do interpretacji i cytowania.
Znaczenie ma również autorytet domeny, aktualność publikowanych informacji, obecność marki w innych wiarygodnych źródłach oraz sposób prezentacji wiedzy.
W wielu przypadkach poprawa struktury treści i rozbudowanie odpowiedzi na konkretne pytania użytkowników może zwiększyć szanse na pojawienie się w odpowiedziach generowanych przez AI.
Czy zablokowanie GPTBot w pliku robots.txt spowoduje zniknięcie strony z wyników ChatGPT?
Nie. GPTBot odpowiada przede wszystkim za pozyskiwanie danych wykorzystywanych do rozwijania i trenowania modeli OpenAI.
Jego zablokowanie nie oznacza automatycznego usunięcia strony z wyników wyszukiwania ani odpowiedzi generowanych przez ChatGPT.
Jeżeli chcesz ograniczyć wykorzystanie treści do celów treningowych, a jednocześnie zachować widoczność w wyszukiwaniu, kluczowe jest pozostawienie dostępu botom odpowiedzialnym za indeksowanie i pobieranie treści na potrzeby wyszukiwania, takim jak OAI-SearchBot.
To właśnie one mogą wykorzystywać zawartość witryny podczas tworzenia odpowiedzi i prezentowania źródeł użytkownikom.
Co warto zapamiętać?
- Share of Source zyskuje na znaczeniu jako uzupełnienie tradycyjnej metryki Share of Voice. Coraz ważniejsze staje się nie tylko zajmowanie wysokich pozycji w wynikach wyszukiwania, ale również obecność w źródłach wykorzystywanych przez systemy AI.
- Plik robots.txt wymaga świadomej konfiguracji. Zablokowanie botów odpowiedzialnych za trenowanie modeli nie musi wpływać na widoczność witryny, jednak blokada robotów wyszukujących i indeksujących może ograniczyć jej obecność w odpowiedziach generowanych przez AI.
- Plik llms.txt może ułatwić modelom językowym odnalezienie najważniejszych treści w serwisie i stanowi wartościowe uzupełnienie działań związanych z GEO.
- Ruch pochodzący z platform AI nie zawsze jest jednoznacznie widoczny w Google Analytics 4. Warto utworzyć niestandardowe grupy kanałów, aby skuteczniej monitorować ten segment użytkowników.
- Optymalizacja pod wyszukiwarki AI opiera się na przejrzystej strukturze treści, eksponowaniu najważniejszych informacji na początku sekcji oraz dostarczaniu konkretnych, wiarygodnych danych.
- GEO nie zastępuje SEO, lecz rozszerza je o działania zwiększające szansę na wykorzystanie treści jako źródła informacji w odpowiedziach generowanych przez sztuczną inteligencję, czym jest tożsame z klasycznym procesem ukierunkowanym na pozycjonowanie w epoce AI.

")



")

