

W ogromnym, tętniącym życiem mieście, jakim jest internet, Twoja witryna to okazały budynek. Codziennie odwiedzają go tysiące gości, ale zanim wejdą, spotykają kogoś na progu. To cyfrowy portier, który dyskretnie, lecz stanowczo, kieruje ruchem. Mówi, które drzwi są otwarte dla wszystkich, które prowadzą do prywatnych apartamentów, a które do zaplecza technicznego. Tym właśnie portierem jest niepozorny plik tekstowy o nazwie robots.txt.
Dla portalu informacyjnego, gdzie co minutę pojawiają się nowe treści, a walka o uwagę czytelnika i pozycję w Google jest nieustanna, ten cyfrowy portier to jedna z najważniejszych postaci. Jeden jego błąd, jedno nieporozumienie, może sprawić, że najważniejsze newsy dnia nigdy nie dotrą do czytelników, a całe połacie serwisu staną się niewidzialne dla wyszukiwarek. Z drugiej strony, mądrze skonfigurowany, staje się potężnym sojusznikiem w walce o widoczność, optymalizację i ochronę Twojej najcenniejszej waluty – unikalnej treści.
W tym artykule przeprowadzimy Cię przez wszystkie tajniki pliku robots.txt. Pokażemy, jak z surowego zestawu komend uczynić precyzyjne narzędzie strategiczne, które nie tylko ochroni Cię przed kosztownymi błędami, ale również otworzy nowe możliwości w erze sztucznej inteligencji.
W skrócie
Czym jest plik robots.txt?
To plik tekstowy, który instruuje roboty wyszukiwarek (np. Googlebota), które części Twojej witryny mogą skanować (crawlować), a które mają omijać. Nie służy on do ukrywania stron przed pojawieniem się w wynikach wyszukiwania (indeksowaniem).
Jaka jest różnica między robots.txt a meta tagiem noindex?
Robots.txt mówi robotowi: "Nie wchodź do tego pokoju". Meta tag noindex mówi: "Wejdź, ale nie umieszczaj tego pokoju w publicznym spisie". Jeśli chcesz usunąć stronę z wyników Google, musisz użyć `noindex`.
Dlaczego robots.txt jest kluczowy dla portali informacyjnych?
Pozwala oszczędzać budżet na indeksowanie (crawl budget), blokując dostęp do bezwartościowych sekcji (np. wyników wyszukiwania, paneli admina), dzięki czemu Googlebot skupia się na najważniejszych newsach. Umożliwia także blokowanie botów AI przed wykorzystywaniem treści do trenowania modeli.
Jakie są podstawowe komendy?
- User-agent: Określa, do jakiego robota kierowana jest reguła (np. `Googlebot` lub `*` dla wszystkich).
- Disallow: Blokuje dostęp do określonej ścieżki (np. `/panel-admina/`).
- Allow: Zezwala na dostęp, nawet jeśli nadrzędny katalog jest zablokowany.
- Sitemap: Wskazuje lokalizację mapy witryny.
Jakich błędów unikać?
Najczęstsze pułapki to przypadkowe zablokowanie całej witryny (`Disallow: /`), blokowanie kluczowych plików CSS/JS (co psuje renderowanie strony dla Google) oraz mylenie blokady skanowania z blokadą indeksowania.
Spis treści
- Fundamenty, czyli z kim i jak rozmawiać
- Reguły gry, czyli język, którym mówią roboty
- Strategiczny trójkąt mocy: robots.txt, noindex i X-Robots-Tag
- Plik robots.txt w służbie portalu informacyjnego
- Praktyczne zastosowanie dla wydawców
- Najczęstsze pułapki i jak ich unikać
- Warsztat pracy: testowanie i monitorowanie
- Podsumowanie: Twój cichy, lecz potężny strażnik
Fundamenty, czyli z kim i jak rozmawiać
Zanim zaczniemy wydawać polecenia robotom, warto najpierw zrozumieć, z kim mamy do czynienia i na jakich zasadach przebiega ta komunikacja.
Plik robots.txt opiera się na standardzie Protokołu Wykluczania Robotów (Robots Exclusion Protocol, REP). To pierwsze miejsce, które sprawdza robot wyszukiwarki, taki jak Googlebot, po wejściu na Twoją domenę, aby dowiedzieć się, które części witryny może przeszukiwać, a które mają być pomijane.
Jeśli gubisz się w technicznych terminach lub chcesz wiedzieć, jak te fundamenty wpływają na pozycjonowanie w erze AI, przygotowaliśmy dla Ciebie praktyczną pomoc. Kompletne wyjaśnienie tych i wielu innych pojęć znajdziesz w naszym Słowniczku SEO, który przeprowadzi Cię przez nową rzeczywistość wyszukiwarek.
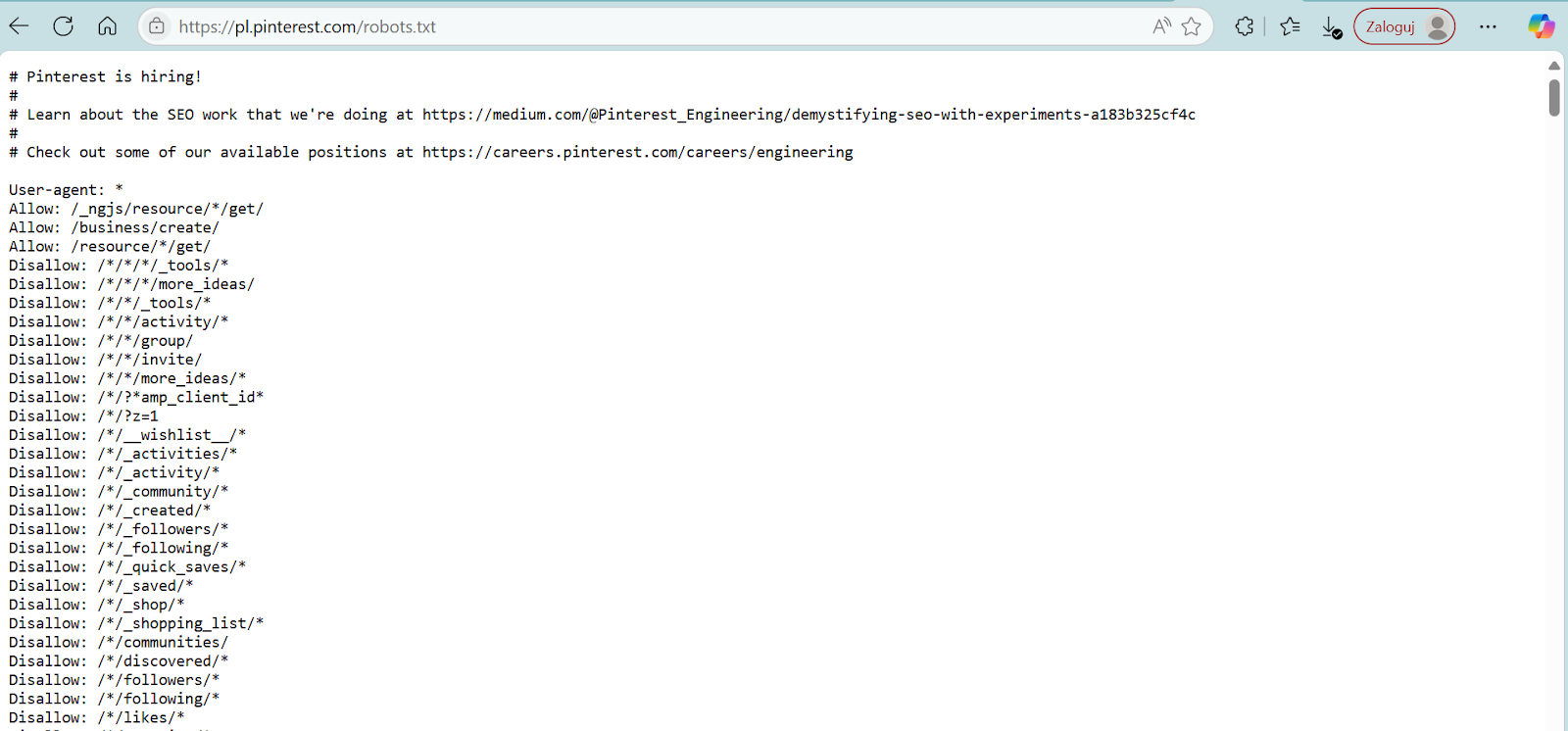
Czym jest plik robots.txt i dlaczego nie służy do ukrywania stron?
Plik robots.txt to standardowy plik tekstowy, który instruuje roboty wyszukiwarek, które części witryny mogą skanować, a które mają omijać; nie służy on do ukrywania stron przed indeksowaniem w wynikach wyszukiwania. Najważniejsza i najczęściej mylona zasada brzmi: robots.txt kontroluje crawling, czyli przeszukiwanie witryny przez roboty, a nie indeksowanie, czyli umieszczanie stron w spisie wyszukiwarki.
Wyobraźmy to sobie na przykładzie:
- Crawling (skanowanie): Portier (robots.txt) zabrania robotowi wejść do pokoju nr 101. Robot grzecznie zawraca i nie sprawdza, co jest w środku.
- Indeksowanie (umieszczanie w spisie): Mimo że robot nie wszedł do pokoju 101, z wielu innych, ogólnodostępnych miejsc w sieci (np. z innych stron) prowadzą do niego linki z tabliczką „W pokoju 101 znajduje się cenny obraz”. Google, widząc te wzmianki, może dojść do wniosku, że pokój 101 istnieje i jest w nim coś ważnego.
Efekt? W wynikach wyszukiwania może pojawić się link do Twojej strony z adnotacją: „Opis jest niedostępny z powodu pliku robots.txt tej witryny”. To sytuacja kuriozalna: nie tylko nie ukryłeś strony, ale też straciłeś kontrolę nad tym, jak jest prezentowana.
Pamiętaj: Jeśli chcesz skutecznie zablokować stronę przed pojawieniem się w Google, musisz użyć innych narzędzi, takich jak meta tag noindex. Plik robots.txt nie jest narzędziem do zapewniania prywatności.
Co więcej, aby robots.txt w ogóle działał, musi spełniać kilka żelaznych reguł technicznych:
- Lokalizacja: Musi znajdować się w głównym katalogu domeny (np. https://twojportal.pl/robots.txt). Każda subdomena (np. sport.twojportal.pl) potrzebuje własnego, oddzielnego pliku.
- Nazwa i format: Nazwa musi brzmieć dokładnie robots.txt (małe litery mają znaczenie) i musi to być prosty plik tekstowy zakodowany w UTF-8.
- Odpowiedź serwera: Jeśli serwer zwróci błąd (np. 503) podczas próby pobrania pliku, Google na 12 godzin całkowicie wstrzyma skanowanie Twojej witryny. Dla portalu informacyjnego to katastrofa – oznacza, że pilne newsy nie trafią do indeksu. Jeśli problem potrwa dłużej niż 30 dni, Google zignoruje plik i zacznie skanować wszystko, co doprowadzi do chaosu i marnotrawstwa zasobów.
Czy Twój URL jest przyjazny Google’owi? Sprawdź to.
Reguły gry, czyli język, którym mówią roboty
Plik robots.txt składa się z grup reguł. Każda grupa zaczyna się od określenia, do jakiego robota jest skierowana, a następnie zawiera listę poleceń, które mówią robotom, co mogą, a czego nie mogą przeszukiwać.
Podstawowe komendy: User-agent, Disallow, Allow, Sitemap
Podstawowe komendy w pliku robots.txt to User-agent, Disallow, Allow i Sitemap (mapa strony). Każda z tych dyrektyw pełni określoną rolę i razem tworzą fundamenty całej konstrukcji pliku, pozwalając precyzyjnie zarządzać tym, które części witryny roboty wyszukiwarek mogą przeszukiwać, a które mają omijać:
- User-agent: identyfikuje robota, do którego kierujemy instrukcję. Na przykład User-agent: Googlebot to polecenie dla głównego robota Google, a User-agent: * oznacza, że reguła dotyczy wszystkich robotów, które nie mają bardziej szczegółowych wytycznych.
- Disallow: blokuje dostęp do wskazanych ścieżek. Na przykład Disallow: /panel-admina/ mówi robotom, aby nie wchodziły do tego katalogu. Pusta wartość, czyli Disallow:, oznacza, że robot może przeszukiwać całą witrynę.
- Allow: zezwala na dostęp do konkretnych podkatalogów lub plików, nawet jeśli nadrzędny katalog jest zablokowany. Przykład: możesz zablokować cały katalog Disallow: /zdjecia/, ale pozwolić na dostęp do podkatalogu publicznego: Allow: /zdjecia/publiczne/.
- Sitemap: wskazuje pełną ścieżkę do mapy witryny, np. Sitemap: https://twojportal.pl/sitemap.xml. To kluczowa dyrektywa, która pomaga robotom wyszukiwarek odkryć wszystkie istotne treści Twojej strony. W przypadku dużego portalu warto wskazać kilka map witryn – osobną dla newsów, wideo, artykułów evergreen czy obrazów.
Magia symboli wieloznacznych: * i $
Jak w prosty sposób zarządzać setkami adresów URL w pliku robots.txt bez tworzenia osobnej reguły dla każdego z nich? W tym celu stosuje się dwa potężne symbole: gwiazdkę * i dolar $. Co to jest gwiazdka i dolar w robots.txt? Gwiazdka zastępuje dowolny ciąg znaków, a dolar oznacza koniec adresu URL, dzięki czemu można tworzyć precyzyjne i wieloznaczne reguły dla robotów wyszukiwarek.
- Gwiazdka * zastępuje dowolny ciąg znaków i jest idealna do blokowania adresów z parametrami. Na przykład reguła Disallow: /*?sort= zablokuje wszystkie adresy URL zawierające parametr sortowania, takie jak .../artykuly?sort=data czy .../komentarze?sort=popularnosc.
- Dolar $ oznacza koniec adresu URL i pozwala na precyzyjne dopasowanie reguł. Przykładowo, Disallow: /*.pdf$ zablokuje dostęp do plików PDF, ale nie do stron, których adres kończy się na .../artykul.pdf.html.
Uwaga SEO: Nieostrożne użycie gwiazdki może prowadzić do poważnych problemów z indeksowaniem. Na przykład reguła Disallow: /artykuly* zablokuje nie tylko katalog /artykuly/, ale także /artykuly-sponsorowane/, co może spowodować poważne straty w ruchu organicznym. Dlatego zawsze warto dokładnie przemyśleć każdą regułę i testować jej działanie przed wdrożeniem.
Hierarchia i porządek – kto tu rządzi?
Roboty nie czytają pliku od góry do dołu w poszukiwaniu pierwszej pasującej reguły. Stosują dwie kluczowe zasady pierwszeństwa:
- Pierwszeństwo w grupie: Jeśli w jednej grupie reguł znajdzie się konflikt między Allow i Disallow, wygrywa reguła bardziej szczegółowa (dłuższa). Allow: /dane/prywatne/ja/ (20 znaków) wygra z Disallow: /dane/ (6 znaków).
- Pierwszeństwo grup User-agent: Robot zawsze wybierze tylko jedną, najbardziej pasującą do niego grupę reguł. Jeśli Googlebot-News znajdzie grupę User-agent: Googlebot-News, całkowicie zignoruje reguły z ogólnej grupy User-agent: * oraz User-agent: Googlebot. Oznacza to, że jeśli chcesz, aby jakiś ogólny zakaz dotyczył również Googlebot-News, musisz go powtórzyć w jego dedykowanej grupie.
Strategiczny trójkąt mocy: robots.txt, noindex i X-Robots-Tag
Skuteczne zarządzanie widocznością w Google opiera się na zrozumieniu trzech narzędzi. Użycie niewłaściwego jest jak próba wkręcenia śruby młotkiem – może i się uda, ale narobi więcej szkód niż pożytku.
Oto ściągawka:
Narzędzie | Komenda dla robota | Kiedy używać? | Wpływ na budżet skanowania |
| robots.txt | "Nie wchodź do tego pokoju." | Do blokowania całych sekcji o niskiej wartości SEO (panele admina, wyniki wyszukiwania, parametry URL) w celu oszczędzania budżetu na indeksowanie. | Oszczędza. Robot nie odwiedza strony. |
| meta noindex | "Wejdź, ale nie mów nikomu, co widziałeś." | Gdy strona musi być dostępna (np. dla użytkowników), ale nie powinna pojawiać się w wynikach wyszukiwania (np. strona z podziękowaniem za subskrypcję, wersje do druku). | Zużywa. Robot musi wejść i przeczytać tag. |
| X-Robots-Tag | To samo co meta noindex, ale dla plików. | Do blokowania indeksacji plików innych niż HTML, takich jak PDF, DOCX czy obrazy. | Zużywa. Robot musi pobrać nagłówki pliku. |
Najpoważniejszy błąd strategiczny: Blokowanie w robots.txt strony, którą chcesz usunąć z indeksu za pomocą tagu noindex. To tworzy paradoks: portier (robots.txt) nie wpuszcza robota do pokoju, więc ten nigdy nie zobaczy tabliczki "nie mów o tym nikomu" (noindex). W efekcie strona nigdy nie zniknie z indeksu Google.
Prawidłowa procedura trwałego usunięcia strony z Google:
- Upewnij się, że strona nie jest blokowana w robots.txt.
- Dodaj na niej tag <meta name="robots" content="noindex">.
- Poczekaj, aż Googlebot ponownie odwiedzi stronę i ją usunie z wyników.
- Dopiero teraz, gdy strona zniknęła z wyszukiwarki, możesz ją zablokować w robots.txt, aby oszczędzać zasoby w przyszłości.
Zarządzanie tymi elementami jest kluczowe, by unikać problemów takich jak duplikaty treści na stronie, które mogą osłabić Twoją widoczność.
Warto też mieć na uwadze kanibalizację słów kluczowych – gdy kilka stron rywalizuje o te same frazy, Google może nie wiedzieć, którą pozycjonować wyżej. Może to osłabić widoczność całej witryny, dlatego precyzyjne stosowanie robots.txt, noindex i X-Robots-Tag pozwala kierować roboty na właściwe strony i unikać tego problemu.
Plik robots.txt w służbie portalu informacyjnego
Dla dużego, dynamicznego serwisu robots.txt to nie opcja, a konieczność. Oto kluczowe strategie.
Zarządzanie budżetem na indeksowanie – bezcenna waluta w SEO
Budżet na indeksowanie (crawl budget) to ograniczona ilość czasu i zasobów, jakie Googlebot poświęci na przeskanowanie Twojej witryny. Jeśli zmarnujesz go na tysiące bezwartościowych stron, może zabraknąć go na Twoje najważniejsze newsy.
Co należy bezwzględnie blokować:
- Wyniki wyszukiwania wewnętrznego: Disallow: *?s=*
- Parametry sortowania i filtrowania: Disallow: *?sort=*, Disallow: *?filter=*
- Parametry śledzące: Disallow: *?utm_*=, Disallow: *?fbclid=*
- Sekcje administracyjne i użytkowników: Disallow: /wp-admin/, Disallow: /login/
- Paginację w głębokich archiwach: Zamiast blokować całe archiwa, zablokuj tylko strony z listami artykułów, np. Disallow: /archiwum/2010/strona/*.
Dobre zarządzanie budżetem to fundament, o którym mówią wszystkie kluczowe zasady pozycjonowania stron.
Nowe wyzwanie: jak rozmawiać z botami AI?
Generatywna sztuczna inteligencja, taka jak ChatGPT, jest masowo trenowana na treściach z internetu, często z naruszeniem praw autorskich. Plik robots.txt stał się głównym narzędziem obrony, pozwalającym wydawcom zakazać wykorzystywania ich pracy do trenowania modeli AI. To już nie jest kwestia techniczna, a biznesowa i prawna.
Przykładowa konfiguracja blokująca najpopularniejsze boty AI:
# Blokada dla botów AI w celu ochrony własności intelektualnej
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: PerplexityBot
Disallow: /
Warto śledzić ten temat, bo ochrona treści staje się równie ważna, co jej tworzenie, zwłaszcza w kontekście narzędzi takich jak ChatGPT, o którym warto wiedzieć więcej, zanim zacznie pisać za Ciebie.

Praktyczne zastosowanie dla wydawców
Wydawcy mogą stosować robots.txt do ochrony swoich treści premium, artykułów eksperckich i innych wartościowych materiałów przed wykorzystywaniem ich przez boty AI, w tym narzędzi tworzących AI Overviews czy generujących streszczenia AI.
AI Overviews to automatyczne podsumowania i przeglądy treści, które modele sztucznej inteligencji tworzą na podstawie istniejących artykułów, a streszczenia AI skracają dłuższe teksty do wersji przystępnych dla użytkowników lub systemów agregujących informacje.
Dzięki odpowiedniemu zarządzaniu robots.txt wydawcy zachowują kontrolę nad swoją własnością intelektualną, jednocześnie pozwalając wyszukiwarkom indeksować treści publiczne i utrzymać widoczność w SEO. Takie świadome zarządzanie robotami jest dziś nie tylko narzędziem technicznym, lecz elementem strategii biznesowej i ochrony marki.
Jednocześnie, wraz z wprowadzeniem przez Google tzw. Trybu AI, czyli trybu wyszukiwania generatywnego, który agreguje odpowiedzi bezpośrednio na stronie wyników, wydawcy muszą brać pod uwagę dodatkowy kontekst: ich treści mogą zostać przetworzone i zaprezentowane użytkownikowi bez potrzeby kliknięcia w link. Jeszcze bardziej zwiększa to znaczenie świadomego zarządzania dostępem botów do danych i decydowania, które treści są przeznaczone do indeksowania, a które pozostają chronione.
Jeśli chcesz dowiedzieć się, jak połączenie wydajności strony, odpowiedniego CMS i technicznej optymalizacji wpływa na widoczność w Google i pozwala zachować kontrolę nad sposobem prezentacji Twoich treści w wynikach wyszukiwania, przeczytaj artykuł „Jak szybkość strony i dobry CMS decydują o Twoim SEO”.
Precyzyjne sterowanie dla Google News i Google Images
Jako portal, zależy Ci na obecności w różnych usługach Google. Dzięki robots.txt możesz precyzyjnie sterować dostępem dla dedykowanych robotów.
- User-agent: Googlebot-News: Ten robot odpowiada za treści w Google News – kluczowym kanale dystrybucji dla wydawców. Zazwyczaj powinieneś zapewnić mu pełny, nieograniczony dostęp.
- User-agent: Googlebot-Image: Kontroluje skanowanie obrazów.
- User-agent: Googlebot-Video: Odpowiada za treści wideo.
Możesz stworzyć dla nich osobne reguły, np. zezwalając Googlebot-News na wszystko, a jednocześnie blokując Googlebot-Image dostęp do galerii niskiej jakości. To pozwala również na lepsze targetowanie treści do Google Discover, które może przynieść ogromny ruch.
Najczęstsze pułapki i jak ich unikać
Jeden nieostrożny ruch może spowodować, że Twoja witryna zniknie z Google na wiele dni. Oto lista grzechów głównych:
- Wgranie na produkcję pliku z wersji testowej. Najgorszy koszmar każdego SEO-wca. Plik z jedną, zabójczą linijką: User-agent: * Disallow: /. Efekt: cała strona zablokowana.
- Literówki i błędy składni. Disalow zamiast Disallow lub brak dwukropka unieważnia całą regułę.
- Zbyt zachłanne użycie *. Disallow: /p* miało zablokować /prywatne/, a zablokowało też /polityka/ i /pogoda/.
- Blokowanie kluczowych plików CSS i JavaScript. Google musi "zobaczyć" stronę tak, jak widzi ją użytkownik. Zablokowanie tych zasobów sprawi, że Google zobaczy "rozsypaną" stronę, co drastycznie obniży jej ocenę. To fundamentalny aspekt, wpływający na wskaźniki Core Web Vitals.
- Konflikt robots.txt z noindex. Jak omówiono wcześniej – to prosta droga do frustracji.
Warsztat pracy: testowanie i monitorowanie
Konfiguracja robots.txt to nie jednorazowe zadanie, a ciągły proces. Zawsze testuj zmiany przed i po wdrożeniu.
Niezbędne narzędzia:
- Tester pliku robots.txt w Google Search Console: To Twoje oficjalne i najważniejsze narzędzie. Pozwala wkleić nową wersję pliku i sprawdzić "na sucho", jak Google zinterpretuje reguły dla konkretnego adresu URL, zanim wgrasz plik na serwer.
- Raport dotyczący pliku robots.txt w GSC: Nowsze narzędzie, które pokazuje, czy Google może pobrać plik i czy nie znalazł w nim błędów.
Podsumowanie: Twój cichy, lecz potężny strażnik
Plik robots.txt to prosty plik tekstowy umieszczany w katalogu głównym strony, który mówi robotom wyszukiwarek, jakie strony mogą indeksować, a które mają omijać. Dzięki niemu możesz kontrolować, które treści trafiają do wyszukiwarek, oszczędzać budżet indeksowania i chronić wrażliwe lub nieistotne dla SEO materiały. Choć na pierwszy rzut oka wygląda niepozornie, jego prawidłowe wykorzystanie ma realny wpływ na widoczność strony i sposób, w jaki roboty interpretują Twoją witrynę
Choć wygląda jak relikt z początków internetu, dziś pełni znacznie ważniejszą rolę niż kiedykolwiek. To nie jest już tylko element techniczny – to manifest biznesowy i prawny, za pomocą którego zarządzasz relacjami z całym cyfrowym ekosystemem – od kluczowych dla Twojego biznesu robotów Google, po boty AI, które chcą wykorzystać Twoją pracę.
Dla portalu informacyjnego to narzędzie absolutnie krytyczne - tak samo jak odpowiednia struktura twojej witryny zgodna z SEO. Pozwala oszczędzać bezcenny budżet na indeksowanie, zapobiegać chaosowi związanemu z indeksowaniem nieistotnych stron i chronić Twoją własność intelektualną. Pamiętaj, aby traktować go z należytą uwagą – bo dobrze skonfigurowany portier to gwarancja porządku, bezpieczeństwa i płynnego ruchu w Twoim cyfrowym budynku.
Jeśli publikujesz artykuły sponsorowane, warto też zajrzeć do poradnika Tag kanoniczny w artykule sponsorowanym – jak uniknąć kary od Google i nie stracić na SEO. Dowiesz się z niego, jak technicznie zabezpieczyć swoje treści i w pełni wykorzystać ich potencjał SEO.

")



")

