
I’ve seen too many campaigns where companies pay premium prices for links that don’t move the needle because of one technical oversight: duplicate content.
It’s a common skepticism: Why pay for a placement if Google might just see it as a copy and ignore it? If you simply copy-paste an article to a publisher’s site without a strategy, you aren't building SEO; you might be burning your budget on links that provide zero value. To ensure your budget is well-spent, it helps to know what SEO metrics like Ahrefs DR and Majestic TF actually mean when buying sponsored articles.
So, here is the real question: How do you use the Canonical Tag to ensure those expensive links provide long-term ROI instead of getting your site penalized?
In this guide, we’ll cut through the noise and show you exactly how to master the canonical tag (rel="canonical") and the noindex meta tag so your investment actually delivers results.
In Brief: The Executive Summary (FAQ)
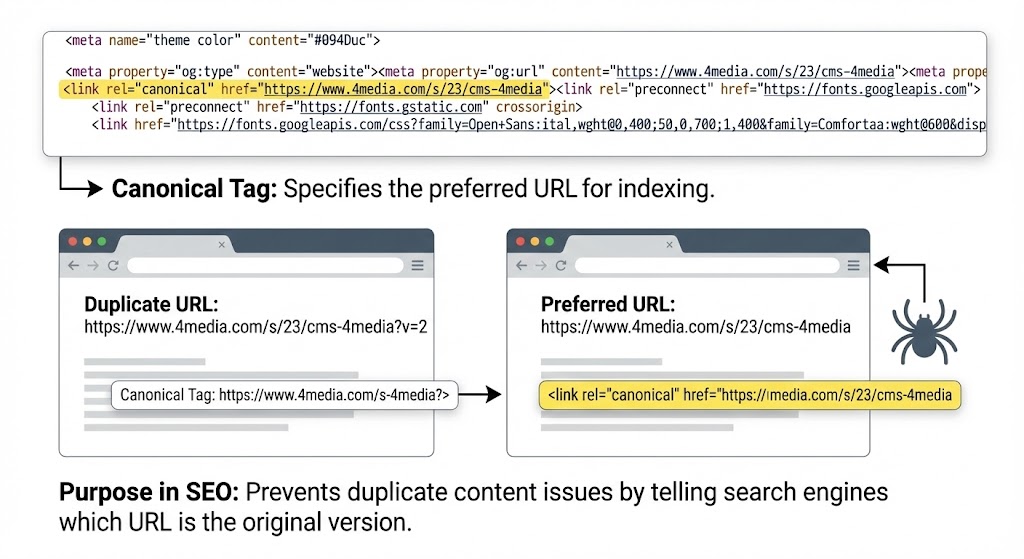
What is a canonical tag (rel="canonical")? It is a snippet of HTML code that tells search engines which version of a duplicate page is the original. It concentrates all "SEO juice" onto one main URL, preventing duplicate content penalties.
How do I manage duplication in sponsored articles? When the same article lives on both a publisher's site and a sponsor's site, you must point to the master copy. Google has two distinct recommendations:
- For your own network of sites: Use the canonical tag (rel="canonical") pointing to the main version.
- For external partners (Syndication): Use the noindex meta tag on the copies so they don't clutter search results.
What are the main canonical strategies?
- Self-canonical: The publisher claims the content as original (most common).
- External-canonical: The publisher points to the sponsor's site as the original, passing all SEO value to them.
- Meta noindex: One site (usually the copy) is completely hidden from Google's index.
What mistakes should I avoid? Always mark paid links with rel="sponsored", never make typos in canonical URLs, and never use canonical and noindex on the same page simultaneously.

Table of contents
- How Does Google Know Which Page Is the Original?
- Sponsored Articles: The Silent SEO Killer
- Canonization or Deindexing? Google’s Official Playbook
- Putting It Into Practice: Four Strategies
- Common Canonical Mistakes: Is Your Implementation Leaking?
- Global Algorithms vs. Local Habits
- Tech Support: How CMS4Media Automates the Process
- Take Command of Your Content
How Does Google Know Which Page Is the Original?
To understand exactly how this mechanism works without getting lost in technical jargon, let's visualize the problem of identity using a simple analogy.
Imagine you are trying to find a specific person named Natalie. The problem is that Natalie has three identical twin sisters. They look exactly the same, sound the same, and dress the same. If you saw them all in a room, you wouldn't know who to talk to.
This is exactly the problem Google faces when it crawls the web. It sees four identical pages (Natalie and her sisters) and doesn't know which one is the "Real Natalie" to rank in search results.
The Canonical Tag solves this identity crisis by acting like a custom T-shirt label:
- The Twin Sisters (Duplicate Pages): All the identical sisters wear T-shirts with a big arrow pointing to Natalie that says: "She is the Real Natalie." This is the rel="canonical" tag pointing to the original URL.
- Natalie (The Original Page): Natalie wears a T-shirt that says: "I am the Real Natalie." This is a self-referencing canonical tag.
Thanks to these labels, Google knows exactly who to focus on and ignores the duplicates.
Variation: The "Hide in the Closet" Strategy (Noindex)
Sometimes, pointing to the original isn't enough. In the world of sponsored content, you might use a more direct approach. Imagine the three twin sisters simply hide in the closet when guests arrive. You know they exist, but the guests never see them.
This is the noindex meta tag. It tells Google: "Do not look at this page. Pretend it isn't here." It is often the safest way to handle syndication, ensuring only "Natalie" gets the spotlight.
Sponsored Articles: The Silent SEO Killer
A standard scenario in publisher cooperation often looks like this: A company writes an expert article, pays for publication on a major portal, and then—proud of the work—reposts it on their corporate blog. If you need tips on the writing part itself, be sure to check out how to write a good sponsored article. From a marketing perspective, this makes sense. From an SEO perspective, you are creating a "Natalie and the Twins" problem without the labels.
For Google's algorithms, the situation is black and white: identical content on two URLs equals duplication. To stay safe, you must send two distinct signals:
- The Link Signal: All links leading from the article to the sponsor must be labeled. According to Google guidelines, use rel="sponsored" (or rel="nofollow"). This tells Google, "This is a paid partnership, don't pass standard PageRank."
- The Originality Signal: You must explicitly state which version is the master copy. This brings us back to our dilemma: Labels (Canonical) or the Closet (Noindex)?

Canonization or Deindexing? Google’s Official Playbook
For years, the SEO industry treated the canonical tag as a magic wand for all cross-domain duplication. But the rulebook has changed. Today, Google distinguishes between two scenarios.
Scenario 1: Publishing Within Your Own Network
If you are a publisher owning multiple related sites (e.g., a national news portal and its local subsidiaries) and you cross-post articles, the recommended solution is rel="canonical". To help Google find all these original pages efficiently, understanding the modern sitemap in practice is essential.
By placing a canonical tag on all copies pointing to the main version (The Twins pointing to Natalie), you consolidate SEO power on the primary URL. This prevents keyword cannibalization, where your own sites fight each other for the same spot in search results.
Scenario 2: External Partners (Syndication)
This is where most sponsored articles land. When content appears on a publisher's site and a sponsor's site, Google now recommends using the noindex meta tag on the copies.
Why? Because sometimes Google ignores the labels (canonical tags), especially if the Twins look slightly different (edited content). The noindex tag (The Closet) is a clean cut. It asks Google simply not to index the copy at all. It is the safest way to ensure that only the version you want to rank appears in search.
Putting It Into Practice: Four Strategies
The right strategy depends on your business goals and the contract between the sponsor and the publisher. Here are the four most common approaches using our metaphor.
Strategy 1: Self-canonical – The Publisher is King
In this model, the publisher is "Natalie." The article on the publisher's site points to itself as the original.
- The Setup: The publisher wears the "I am the Real Natalie" shirt. If the sponsor reposts the article, they should go into the closet (noindex).
- Pros: The publisher builds SEO value. All link juice and organic traffic stay on their domain.
- Cons: The sponsor gets no direct SEO benefit from the content itself, only branding and referral traffic. To properly track that referral traffic, you should consult a technical guide to Google Analytics 4 and Search Console.
Strategy 2: External-canonical – Power to the Sponsor
The publisher admits they are just a "Twin Sister." They place a canonical tag pointing to the article on the sponsor's website.
- The Setup: The publisher wears a shirt with an arrow pointing to the sponsor's website saying "She is the Real Natalie."
- Pros: The sponsor maximizes SEO benefits—Google sees their domain as the authority.
- Cons: The publisher forfeits SEO benefits. Their version likely won't appear in search results.
Strategy 3: Meta Noindex – The Clean Cut
Instead of pointing fingers, one site (usually the copy) applies a noindex tag.
- The Setup: The copy stays in the closet. Only the original is visible to Google.
- Pros: Total control and a clear signal. Zero risk of cannibalization.
- Cons: The no-indexed page generates zero organic search traffic.
Strategy 4: No Tags – The Highway to Hell
Publishing identical content in two places with zero signals.
- The Setup: Natalie and her three identical sisters stand in a line, with no labels. You ask Google to "pick the Real Natalie."
- Consequences: Google gets confused. It might pick the wrong one, or worse, decide to index none of them (demote both sites). If you find your pages disappearing entirely, you might be falling victim to one of the 10 reasons why your site is invisible on Google. You risk diluting ranking power and creating a mess. A mess here can quickly undermine a solid foundation, which is why site structure optimization should always be a priority.
Common Canonical Mistakes: Is Your Implementation Leaking?
The devil is in the details. Even a sound strategy fails if implemented poorly.
- Missing rel="sponsored": A fundamental error. Google treats unmarked paid links as an attempt to manipulate rankings.
- Broken Canonical URLs: Typos, using HTTP instead of HTTPS, or pointing to a mobile URL from a desktop page can render the tag useless. For a deeper dive into crafting perfect links, our ultimate guide to URL structure for SEO is a great resource.
- Mixing canonical and noindex: Placing both on the same page sends a conflicting signal. It's like wearing a "She is the Real Natalie" shirt while hiding in the closet. Google will usually prioritize the closet (noindex), meaning your canonical hint is ignored.
- Canonicalizing Different Content: The tag is for identical or near-identical pages. If the publisher heavily edits the text (Natalie gets a haircut and dyes her hair), Google may realize they aren't identical anymore and ignore the tag, treating both pages as unique. If those edits are being done with artificial intelligence, keep in mind the 10 things you should know about ChatGPT before writing articles.
Global Algorithms vs. Local Habits
While Google’s algorithms are global, SEO habits vary by market. These algorithms are also shifting rapidly, making it crucial to know how to survive and rank in the era of generative search. The industry has historically leaned heavily on rel="canonical" for cross-domain issues. Google’s newer guidance favoring noindex for syndication is still gaining traction.
This means you might encounter partners who insist on rel="canonical" out of habit, even where noindex is safer. It’s not necessarily "wrong," but being aware of these nuances helps in negotiation. The key is understanding the consequences of each choice.
Tech Support: How CMS4Media Automates the Process
Managing tags, ads, and sponsored content manually is a recipe for burnout. This is why publishers are turning to integrated systems like CMS4Media—a platform built for monetization.
It directly addresses these challenges:
- Integrated Ad Management: Connected with Ads4media.online, it allows seamless ad code implementation across multiple portals.
- Advanced Monetization: Built-in paywall functionality (Stripe/PayPal) opens new revenue streams.
- Better Targeting: An onboard DMP (Data Management Platform) improves ad targeting, leading to higher rates.
- Measurable Results: Clients report an average 32% increase in ad revenue and a 45% boost in unique visitors.
Choosing a CMS that handles the technical heavy lifting allows you to focus on strategy rather than fixing code. And speaking of technical heavy lifting, a good CMS should also help you maintain solid Google Core Web Vitals.
Take Command of Your Content
Managing sponsored articles is about more than just good copy. It’s about technical control. Remember three rules:
- Always Label Links: rel="sponsored" is your safety belt.
- Choose Your Strategy: Decide who gets the "Original" status (who is Natalie) and stick to it.
- Follow the Leader: When syndicating to partners, consider noindex (the Closet strategy) as the safest modern approach.
By following these rules, your content marketing investment will build your brand's authority rather than confusing the search engines. Mastering these technical details is just one part of the puzzle; you also need a broader strategy for surviving AI in 2026.

")

